背景
人类社会历史是螺旋前进的,科技史亦然。从1950s提出Artificial Intelligence概念至今,AI技术已经经历了多次春、冬季交替演进(AI Winter)。上一代AI技术(1970s-1980s)是基于符号(symbolic)的计算系统,以LispMacine、专家系统、日本第5代计算机系统等为代表。这类技术在知识表示、逻辑推理上有优势,但是不具备模式识别能力。此后基于统计学的MachineLearning复兴(1990s-2000s),虽然彼时AI尚不普遍,但相关的数据统计分析、大数据系统、云计算基础设施,在这一时期并行快速发展。Hinton等人2006年提出“深度学习”概念后,随着AlexNet (2012) 和AlphaGo (2015) 的成功,AI技术逐步从基于浅层统计模型(例如SVM)向深层神经网络(例如CNN)演进;Google研究人员于2017年提出Transformer架构,之后神经网络的复杂度呈指数级上升,其性能也推动了NLP和相关领域的技术变革。OpenAI 2022年基于Transformer架构实现AI的里程碑式创新(ChatGPT),再次燃起人类对AGI的热情和渴望。本文结合过去二三年的AI技术热点和发展脉络,对Data&AI前沿技术和2025年的趋势进行分析,并探讨笔者对AGI实现路径的一些思考。
Transformer介绍
Transformer属于深度神经网络的架构之一,具体属于无监督的自回归预训练模型。无监督(Self-supervised)意味着不需要人工标记数据,模型自动学习中间特征表示,并具备迁移学习能力。自回归(Auto-regressive)是预训练模型的方法之一,其本质在“回归”,基于过去的数据预测未来,例如LLM预测下一个token。预训练指通过大量的随机样本对模型进行拟合,尚不具备(高效的)场景化问题解决能力,因此需要post-train阶段对模型进行微调,以适应下游问题和场景。
与AR相关的另一种预训练方法是自编码(Auto-encoding),如BERT提出的掩码语言模型,通过遮挡样本随机位置的信息,模型可结合上下文信息,学习丰富的语言符号表示,方便下游复用。
AR和AE是两种常用的生成式语言模型的预训练方法,但并非全部,例如XLNet提出排列语言模型实现双向上下文的结合,同时具备AR和AE的优势。此外,虽然强化学习和对抗学习也在某些LLM训练中(如DeepSeek-R1)发挥了重要作用,但其作为核心训练算法的模型和应用场景,仍有待进一步探索。在图计算领域,虽然AR和AE同样被用来训练图节点的低维表示,并在下游图任务中取得了不错的效果,但是Graph-native的训练方法仍在探索阶段。
AR和AE模型,在NLP领域取得了巨大成功。透过表象看本质,在当前的语言模型训练中,并未基于自然语言单位的语义(概念)进行学习,而是基于token组合的统计规律。换句话说,在token集合展开的序列空间里,实际的自然语言样本是空间的子集,Transformer通过神经网络参数捕获了这个子空间的序列模式。只要神经网络表示的参数空间足够覆盖样本序列空间,便能够成功学习子集的表示。在这个意义上,AR和AE的训练方法对于“有限元素集合的序列空间”具有普适的学习能力。
Transformer架构目前已在自然语言之外的多个领域得到实践并达到SOTA:
- 计算机视觉:图像分类[ViT]、目标检测[DETR]、图像生成[TransGAN]、图像分割[SETR]
- 生物信息学:蛋白质结构预测[AlphaFold2]、基因序列[Lee2022]、单细胞组学[Szalata2024]
- 时间序列分析:天气预测[FuXi]、时空动态预测[Li2024]、金融预测[Galformer]
- 语音处理:语音识别[Conformer]、合成[Tacotron]
- 多模态学习:图文生成[DALL-E]、视频理解[VideoBERT]
从以上实践可见,通过将领域内问题通过适当的方法转换成序列数据后,构建离散元素集合,Mirchandani2023总结出Transformer是通用序列模式学习器 。对于一个封闭/半封闭式的复杂系统,当系统内部具有有限状态集合、或有限状态生成规则(如明确的物理规律),Transformer能够较好地对这类系统行为建模。
技术热点和创新趋势
LLM工程优化
对Transformer极致优化背后的逻辑是大家对Scaling-law的信奉。随着训练数据规模和参数量(trilion-scale)的提升,人们期望通过工程上极致的优化,在有限资源下训练更大的模型,期待再次出现类似GPT-3的涌现时刻。
在此背景下,一方面是粗放式地堆叠计算卡,另一方面是类似DeepSeek团队对Transformer的每个部分做极致优化:计算效率(如注意力机制、长序列优化、并行训练)、内存占用(如浮点精度、注意力窗口)、推断/Inference优化(如KVCache、蒸馏、量化、wafer级加速)等。
工程优化是LLM产品化和业务化降低成本的必经之路,但单纯地追求scaling-law并不能让我们更接近AGI或human-level intelligence,这是Transformer也是神经网络算法的内在限制(见下文后LLM时代)。
所以无论Jason Huang多么大声疾呼scaling-law无比重要,研究人员也要保持理性和洞察力,理解、掌握并跨越scaling-law,寻找那把真正能打开AGI大门的钥匙。
LLM知识增强
LLM架构自身有几个显著缺陷:
- 知识更新成本高:这是神经网络基于参数的隐知识表示(latent knowledge representaiton LKR)的限制,无法复用、局部更新和迁移知识。理解LLM的LKR是可解释AI领域关注的重要问题之一。如何复用LKR或寻找通用知识表示,也是AGI需要攻克的技术难点之一。
- 生成“幻觉”:虽然LLM注意力模块是确定性的,即模型训练好后,对于任何一个注意力模块给定输入后,输出是确定的;但LLM依然有生成幻觉问题,原因是多方面的[Huang2025],例如训练数据缺陷、错误传导、无自指导致的弱一致性等。
- 可解释和可控性不足:这也是神经网络架构的固有限制,几乎所有的post-train工作都只能在e2e下进行。虽然相关的LLM probing和editing技术也在研究,但尚无稳定可靠的方法论或工具。神经网络模型的过拟合和泛化,就像夜空中的启明和长庚,本为一体却又相互矛盾。
尽管如此,LLM作为自然语言处理领域的一项颠覆性技术,其价值对于社会生产力的潜在提升,也是不容忽视的。为了利用更新信息、或私有域数据,Retrieval Augmented Generation (RAG) 的工作流被提出来。从最初基于文本块向量的VectorRAG到语义表示更丰富的GraphRAG,2024可谓是RAG大年,相关技术已经成为LLM+商业化落地的基石,也是未来AI-native apps的必备技能。
同时,结合数据和算法的增强,在减小模型尺寸的同时保持LLM的有效知识密度(笔者注:有效知识密度,定义为LLM内的知识完备度与模型复杂度–等效vanilla transformer架构的参数量–的比值),为模型的推理质量、推理深度的增强铺平了道路。诚如Ilya Sutskever所言,Internet是LLM时代的化石燃料。在数据规模有限的情况下,深入理解LLM原理,磨炼算法才是正途(见下文可解释性)。
从即时推断到深度推理
自Chain of Thought提出以来,人们在优化LLM解决复杂推理问题的同时,也在不断探索如何通过计算机模拟人类思考(Turing’s imitation game)。DeepSeek的出圈,一方面是对工程极致的追求,更重要的是开源了GPT-4级、具备深度推理能力的模型训练方法,人们在享受GPT-4级免费模型的同时,研究人员再也不用猜测其内部训练机制了。
如果推断 (inference) 是对模型在训练阶段捕获的隐知识表示(token序列模式)的浅层反馈,那推理 (reasoning) 便是对这些隐性知识的深度挖掘。以自然语言为表示的推理,演绎出新的知识,最新成果例如OpenAI o1/o3-mini, DeepSeek-R1, Google Gemini Flash Thinking。Dr. Wolfe最近有篇精彩的总结文章。
对于推理机制和算法的深入研究,或许是ChatGPT引领的AI复兴留给未来AGI科技的重要资产之一,也是未来LLM商业化的核心竞争力。深度推理之于LLM,类似于PageRank算法之于搜索引擎。商业巨擘基于LLM技术对自身内部无处不在的数据Silo进行整合,基于深度推理开发出更具吸引力产品体验。近期上线的Gemini Flash Thinking with apps功能,基于整合Youtube、GoogleMap的数据,Gemini2展现出比单纯模型推理、RAG更为强大的实际问题解决能力。但因为涉及核心的业务逻辑,背后的深度推理链未来可能不会再采取开源开放的态度。
LLM可解释性
和单纯用好LLM相比,理解LLM的工作机制,深入探索知识表示、记忆、推理、遗忘等深层次和人类认知相关的基础技术,更有助于迈向AGI。因此AI开拓者们在Nature大声呼吁,我们应该注重neuroscience和AI的跨领域研究(NeuroAI),加强认知、神经科学等基础领域的教育和资金投入。
神经网络的层数越多,参数空间越大,可存储的信息越多。在神经网络中,模式以高维向量表示,在LLM中也称作隐知识表示。由于训练语料体量大,即使采用数据清理去噪,也无法获得一致性强的原始知识。实践表明,数据Bias和人为构造攻击数据,很容易对模型的行为造成影响。
在深入理解LLM机制上,Zhou2024发现参数越大、post-train阶段指令调教越多的LLM稳定性越差。在内部激活神经元不可控的前提下,针对特定领域问题的fine-tuning/filtering会加速其他领域知识的遗忘。Mahowald2024的研究揭示了LLM对Formal语言能力(指对语言规则和统计规律的掌握,如翻译)较强,但是Functional语言能力(指利用语言在现实场景应用,如推理)较弱;这与当前LLM向DeepReasoning方向演进的趋势相符。
事实上,由于训练数据内部知识的不一致性,造成LLM内部的知识冲突,Xu2024表明这种冲突是普遍存在、且内生的,需要更加底层的变革。因此,LLM是弱一致性(weak-consistency)模型。和一致性相关有个著名的Gödel不完备定理,其表示对于任意的formal system,完备性(completeness)和一致性(consistency)无法兼而有之。Pérez2021证明Transformer一定约束下是turing-complete,而turing-complete system是formal system。由此可见,LLM在一定约束下满足Gödel不完备定理,在追求知识量(高完备性)的前提下,势必会破坏知识表示的一致性:这如同紧箍咒,定位了通用单一LLM模型的能力边界。因此笔者认为,这也预示着MoE架构比当下流行的通用单一模型更有前景。
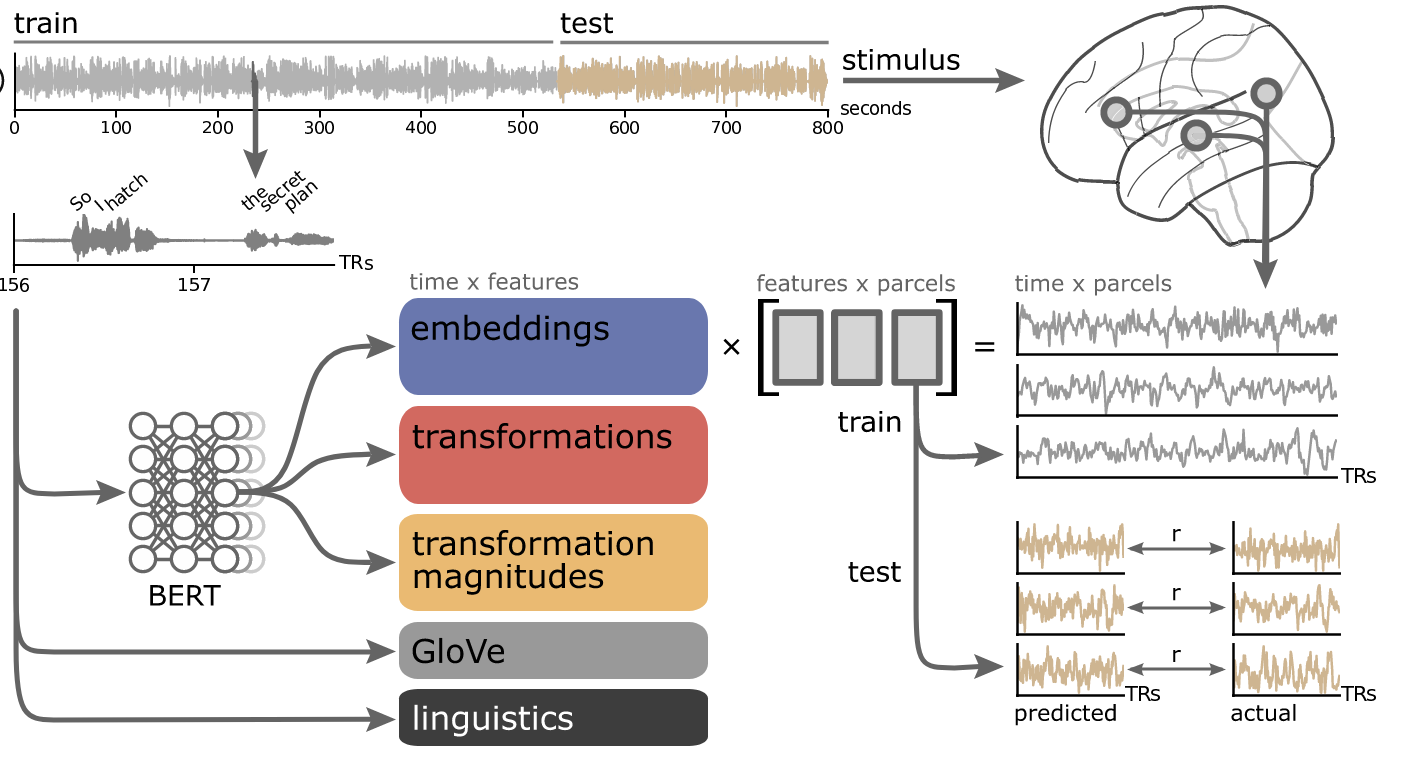
除此以外,即便LLM是个黑盒,其对自然语言模式、尤其对基于语言的逻辑推理的捕获,让人们不禁好奇:这种类人思考的机制的本质是什么?在NeuroAI领域,结合LLM和大脑fMRI数据的研究,Mischler2024和Kumar2024揭示了LLM工作机制和人脑皮层的神经信号处理在宏观上的相似性。虽然仍处于初期研究阶段,该领域的研究或许是下一代AGI技术的突破所在。
后LLM时代:两种潜在的AGI路径
它山之石可以攻玉。近年来,人们经过对LLM及Transformer架构的深入研究,在通过工程化增强LLM实用性的同时,也逐步认识到其内在局限性。从AI概念提出至今,人们不断对“机器如何模拟人类”的想法进行实践,经典的研究领域包括认知框架(Cognitive Architectures)、形式系统(Formal systems)、心智理论(Theory of Minds)、世界模型(World Models)等。虽然这些领域的问题在实践中尚未得到完全的解决,但其思想沉淀对AGI研究依然有所启示。
基于当前数据规模和算力提升,我们应该重新审视AI的发展历程,汲取前人思想和实践经验,从宏观视角探索潜在的AGI实现路径。笔者以为,当下有两个潜在的AGI实现路径值得关注:世界模型和神经符号AI(Neuro-symbolic AI)。
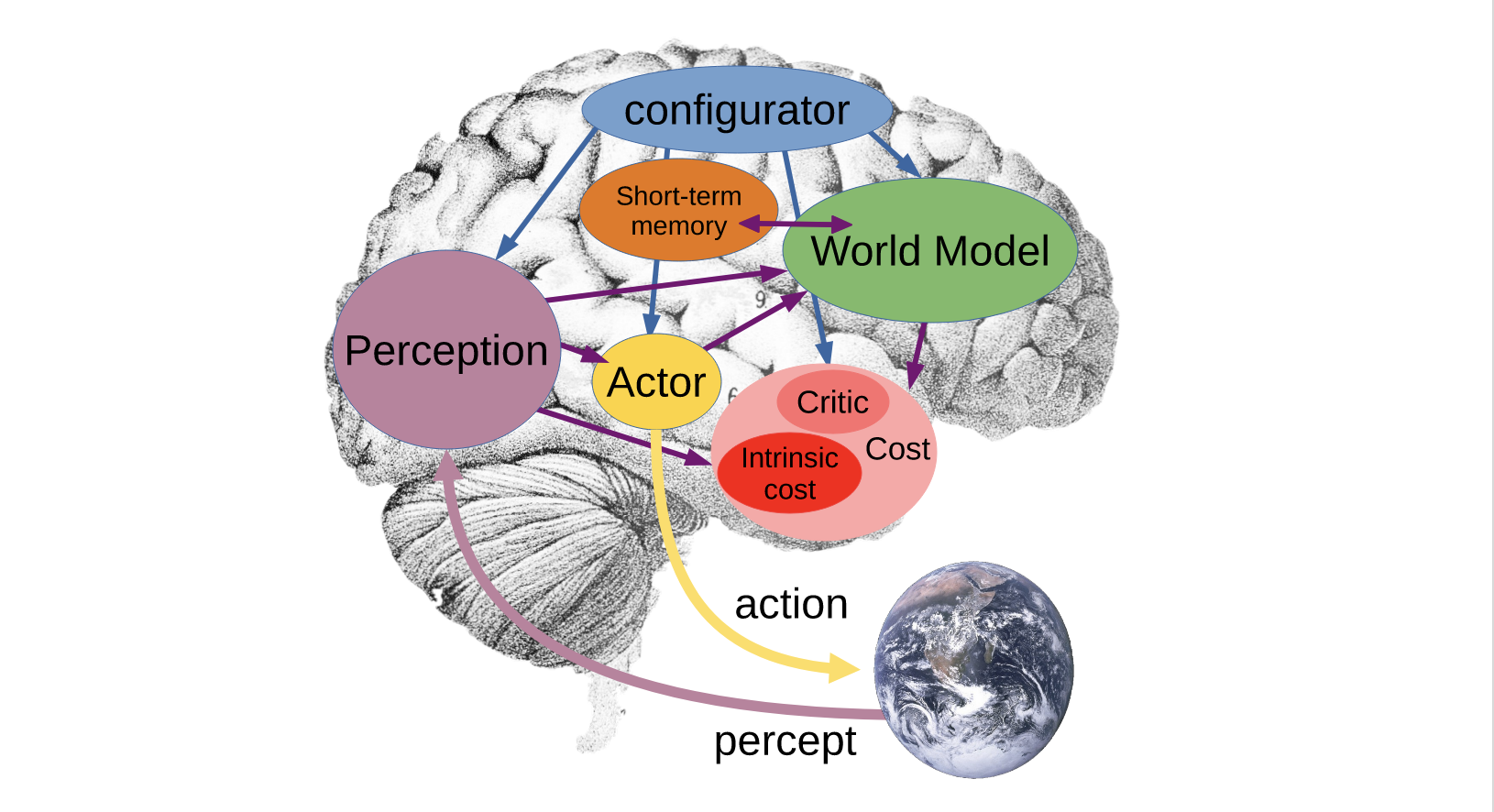
世界模型的思想与AI发展一脉相承,其核心思想从第一性原理出发,通过描述世界的状态和行为,并定义状态和行为之间的联系,来构建AI模型/系统。世界模型可以用于解决各种问题,如智能体在环境中的规划、决策、行为等。Han2018首次系统介绍了相关概念,并基于vision-memory-controller架构的二维小车游戏展示了世界模型的潜力。LeCun2022提出了基于能量模型EBM和JEPA架构的世界模型实现思路,并在视觉表征、自动驾驶领域得到了实践。李飞飞带队创业成立WorldLabsAI,专注于大世界模型(Large World Models,LWMs),去年12月发布了空间智能计算的第一个成果Generating 3D worlds。Google于2025年1月宣布在DeepMind内部成立专门的WorldModeling团队,以解决世界模型问题。该领域仍处于起步和布局阶段,但其前景令人期待。
神经符号AI是另一个让人兴奋的方向。基于统计模型的机器学习和以LLM为代表的纯神经网络架构,是1990s以后的主流方法,在持续学习、可解释性、常识知识等方面存在缺陷。当前AI研究者的技术栈已鲜有符号AI的影子。符号AI在知识表示、逻辑推理、可解释性等方面有天然优势。在人类的科技理论中,通过领域语言(DSL)而非自然语言表述是普遍的,例如数据符号、逻辑符号、电路符号、编程语言等。基于DSL能够对领域内问题进行精确定义并推理,这也是符号AI的魅力所在。在LLM普遍头疼的数字加减问题,在数据DSL里是最基本的运算。例如Google AlphaGeometry通过神经符号AI解决IMO几何数据问题,新版V2实现了首次超越人类、84%的问题解决率。
在未来的AGI探索中,笔者认为LLM、世界模型、神经符号AI都将是核心技术,并且思想上相辅相成,在世界知识表征、逻辑推理、持续学习、Active Inference等方面实现完全不同于当前AI的范式。
总结
本文围绕当前Data&AI研究领域,对LLM相关的思考、研究、未来世界模型、神经符号AI等方向进行了总结。因为笔者研究视角和精力限制,并未能对当前所有技术趋势进行总结,例如多模态MLLM、Agentic框架也是2025年的热点研究领域,读者可以继续探索AGI的世界。
[版权所有,转载注明出处:https://xiaming.site/2025/02/21/data-ai-trends-2025-zh/]