Intro
An efficient representation of knowledge/logics lies at the core of knowledge computing engines. This requirement is also one of vital pieces of future artificial general intelligence (AGI). Recent success of Transformer architecture in natural language field [1], especially with Large Language Models like GPT-4 and LLaMA series, inspires us that neural networks (NNs) with Attention mechanism are efficient at condensing information and logics encoded in sequential tokens. However these models still remain as a black box about learned inner representation of knowledge (KR). The main reason comes from the token vectorization and high dimensional nature of neural networks with a vast amount (tens to hundreds of billions) of parameters and deep layers.
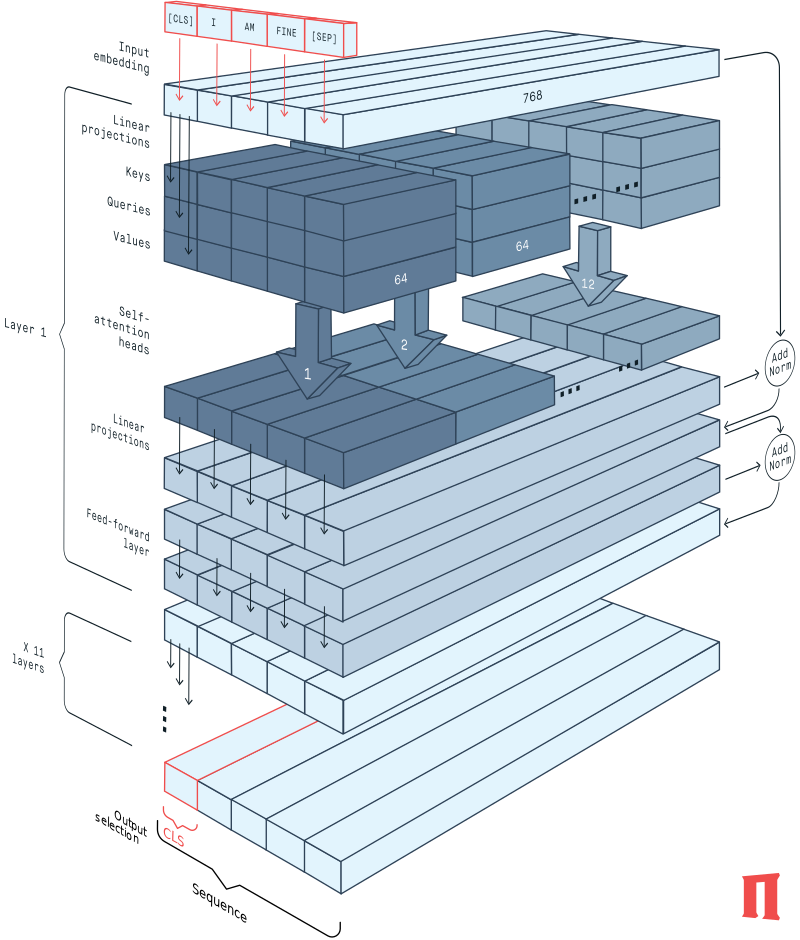
We can imagine LLM as a higher dimensional space that absorbs token occurrence patterns as vectors, and implicit complex logics encoded in their computational relations. Nevertheless we encounter a challenge to interpret, extract and reuse those mastered patterns as explicit knowledge outside a trained model. Also, the representation of specific knowledge piece or logical relation remains unstable as for changes of training context, neural network structure, or the involvement of finetuning techniques. Even models trained against the same datasets at differing times remain incomparable when considering their inner representations.
Hypothesis-1. LLM illustrates the capability to absorb world knowledge as well as reasonable logics, because it masters not the world knowledge per se, but the rules of knowledge organization depicted by natural languages.
A portion of community endeavor is put into reversing engineering the black box by prompt engineering [2], single neuron interpretation [3], network structural analysis [4] etc. We argue that the first principle thinking should be applied to ask the basic and core questions,
- What are we really talking about when saying knowledge representation?
- And what is the straightforward way to represent knowledge?
The answer for the first question is addressed below by several proposed principles about KR. Our answer of the second one is proposed here as “SYMBOLIC”, with a footnote that the concepts of representation and reasoning should be treated independently. Human race has gained abilities to exchange complicated information between each other and convey knowledge between generations after the invention of mnemonic symbol systems. This also enhances our logical reasoning with a ‘inner speech’ mechanism [6], usually driven by symbolic native language. In this sense the symbolic is still a native way of KR.
Limitations of LLM in KR
We have accumulated a large amount of knowledge in different forms, while the symbolic conveys a significant portion (other forms like pictures, sounds, sculptures). It is convenient and efficient to speak or write with mnemonic symbols. What the LLM captures well is the pattern of token sequences, grammar and logics being encoded by token organization (location in sentence, occurrence frequency, relative long- and short-range dependency and so on). Nevertheless there are many other forms of vital symbolic knowledge that cannot fit into the token-sequence model, thus LLM does not deal well with, such as arithmetic equations, physical theories, spatial relations.
Many experiments have shown that LLM fails to calculate addition and multiplication of arbitrary large numbers, much less complicated mathematical theorem understanding. The core reason is that the arithmetic operator, say ‘plus’ or ‘+’, is not just a symbol, but also embodies calculating rules predefined in math. A sequential regression model heavily relying on sample occurrences can not master this kind of implicit knowledge well.
Hypothesis-2. LLM presents superb capabilities in pattern capturing and summarization, while showing an intrinsic weakness to involve the encoded implicit knowledge in symbols.
In the natural language scenario, we are always surprised by the knowledge scale and grammatical generation of LLM, while ignoring the scale of substantial related samples in training datasets and their connections with the generated output. Another explanation for arithmetic weakness of LLM is that we are unable to have a training dataset containing a full arrangement of all possible number calculation.
General Principles of KR
For general concept of knowledge, interpretability, reusability and integration are fundamental practicable demands in our daily usage. We argue that, in a similar sense, knowledge representation in cognitive computing or AGI systems should possess these natures as well. Concretely,
Interpretability, a foundation stone for explainable knowledge systems. We are able to trace the source and reasoning process for output conclusion. It is a vital part to construct paradigm of knowledge discovery, differing from knowledge squeezing and summarization, Hypothesis-1.
Reusability, transferring summarized or discovered knowledge ingredients across different AI systems. In LLM, we assume that complex (implicit) relational dependencies between explicit knowledge ingredients are fetched (Hypothesis-2), similar to the neural pathways created in creatural brains when some direct psychological interactions are built. However, these learned implicit knowledge is locked as black-boxed representations.
Integration, exemplified as a kind of ‘knowledge protocol’ between systems. Almost every branch of our theories owns a suite of symbol framework to present its assumptions, axioms, theorems, deductions etc. This plays an indispensable role in either people communication or system/theoretical framework interaction.
Knowledge Intermediate Representation
To address the challenges observed in LLMs, we suggest that representation should be separated from communication and reasoning processes in knowledge-intensive systems, and a concept of Knowledge Intermediate Representation (KIR) is proposed to fulfil above principles. Some explicit and flexible structures, for example hypergraph, are preferred for KIR. Recent progress in multimodal graph learning [5] also confirms the importance and powerfulness of selecting a suitable presentation paradigm in a sense of fusing multimodal data sources.
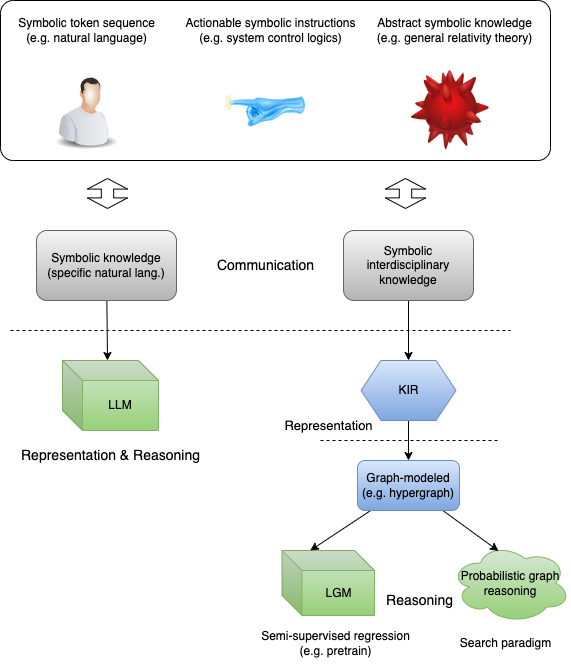
We compare the methodology of KIR with graphical reasoning such as large graph model (LGM) or probabilistic graph reasoning (PGS) with current state-of-the-art LLM technique, as illustrated in above figure. Here we consider the interdisciplinary knowledge presented in symbols, such as natural languages, system control instructions and physical theories. We treat the input human-readable symbols as a human-system interaction interface, defined as the communication part. In left LLM way, all symbolic knowledge in training samples are converted into token sequence and fed into the neural model, where its encoder-decoder structure with attention mechanism is efficient at training parallelly and capturing the long-term dependencies between tokens. Its limitation is coupling of representation and reasoning, and challenges to fulfil those KR principles depicted above.
In our proposed methodology, the general KIR part is introduced, as the right line in above figure. It embodies the principles of interpretation, reusability and integration for KR in a declarative method. A Lisp-like declarative language is recommended. Under the hook, each list expression with a functor and variables could embody both the implicit and explicit knowledge, which is also efficiently handled by other computational techniques, such as symbolic regression [7]. Similar consideration is also made in the project OpenCog Hyperon for MeTTa language [8]. KIR is the kernel of our framework, playing a role like ‘inner speech’ for a cognitive process [6], memorizing ingredients in an artificial mind model (An interesting example is the generative agents from [9] whose KIR is natural language for memorization).
During the reasoning phase, given user’s prompts, tokens are generated recursively by the LLM fine-tuned targeting at specific task. This sequence-in-sequence-out manner constrains LLM’s application in scenarios that the information cannot be transformed into token sequence properly. For example, when human looking at a video of a flock of birds hovering above the forest, birds’ flying patterns and landing location would be inferred and predicted with our born sense of space and understanding of spatial relation of birds, sky and forests. However, it is hard for LLM to formulate these spatial knowledge. Although some showcases imply that LLM can answer space-concept-related physical reasoning question, it is because that similar sequences describing related problems are present in the training set and encoded in the hyper-parameter space.

To conquer this limitation, we propose graph-modeled equivalent (e.g. hypergraph) of KIR before performing reasoning. Also in the birds-hovering example, we could embody the spatial relation of different objects in edges, as well as physical knowledge encoded in edge-bundled functors. Ektefaie etc. [5] employ a unified graph model to perform multimodal learning, which shares the similar idea. In the reasoning procedure, the problem is formulated as partial substitution of masked subgraphs, in other words, performing subgraph matching given a variable-embedded graph (variable grounding). We categorize techniques into two groups, searching paradigm and graph neural network (GNN) paradigm. Both could meet our requirements, but have differences in the scale of searching space and computing efficiency.
Contd. We leave the discussion of graph-centric paradigm and its integration with KRI in next part.
Summary
This article shows a blueprint of my project LaCogito towards general cognitive/knowledge computing infrastructure. It summarized my recent thinking about KR and expected related principles to develop a knowledge-intensive system. After a technical deduction, KIR seems to pave a new way to integrate both explicit and implicit knowledge in a unified framework. Also graph-centric architectures have shown potentials to perform reasoning on KIR base.

This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
References
[1] Lin T, Wang Y, Liu X, Qiu X. A survey of transformers. AI Open. 2022 Oct 20.
[2] White, J., Fu, Q., Hays, S., Sandborn, M., Olea, C., Gilbert, H., Elnashar, A., Spencer-Smith, J. and Schmidt, D.C., 2023. A prompt pattern catalog to enhance prompt engineering with chatgpt. arXiv preprint arXiv:2302.11382.
[3] Dai, D., Dong, L., Hao, Y., Sui, Z., Chang, B. and Wei, F., 2021. Knowledge neurons in pretrained transformers. arXiv preprint arXiv:2104.08696.
[4] Li, M. and Zhang, Q., 2023. Does a Neural Network Really Encode Symbolic Concept?. arXiv preprint arXiv:2302.13080.
[5] Ektefaie, Y., Dasoulas, G., Noori, A., Farhat, M. and Zitnik, M., 2023. Multimodal learning with graphs. Nature Machine Intelligence, pp.1-11.
[6] Alderson-Day, B. and Fernyhough, C., 2015. Inner speech: development, cognitive functions, phenomenology, and neurobiology. Psychological bulletin, 141(5), p.931.
[7] Cornelio, C., Dash, S., Austel, V., Josephson, T.R., Goncalves, J., Clarkson, K.L., Megiddo, N., El Khadir, B. and Horesh, L., 2023. Combining data and theory for derivable scientific discovery with AI-Descartes. Nature Communications, 14(1), p.1777.
[8] Goertzel, B., 2021. Reflective Metagraph Rewriting as a Foundation for an AGI” Language of Thought”. arXiv preprint arXiv:2112.08272.
[9] Park, J.S., O’Brien, J.C., Cai, C.J., Morris, M.R., Liang, P. and Bernstein, M.S., 2023. Generative agents: Interactive simulacra of human behavior. arXiv preprint arXiv:2304.03442.
Acknowledge of images, ‘awesome-transformer-nlp’ attributed to project awesome-transformer-nlp